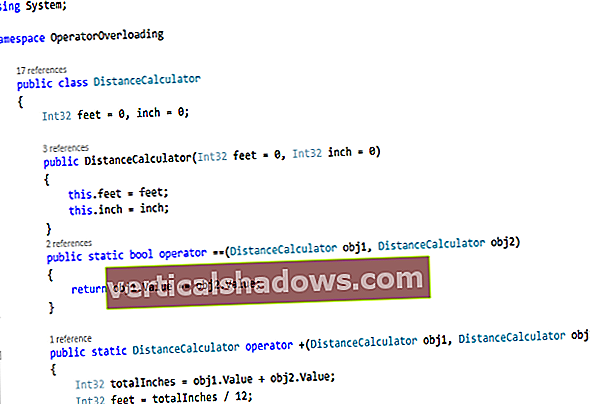
Klausykite bet kokio pokalbio apie didelius duomenis ir tikriausiai išgirsite paminėjimą apie „Hadoop“ ar „Apache Spark“. Čia trumpai apžvelgiama jų veikla ir jų palyginimas.
1: Jie daro skirtingus dalykus. „Hadoop“ ir „Apache Spark“ yra didžiųjų duomenų sistemos, tačiau jos iš tikrųjų nėra skirtos tiems patiems tikslams. „Hadoop“ iš esmės yra paskirstyta duomenų infrastruktūra: ji paskirsto didžiulius duomenų rinkinius keliuose mazguose prekių serverių grupėje, o tai reiškia, kad jums nereikia pirkti ir prižiūrėti brangios pasirinktinės įrangos. Be to, jis indeksuoja ir seka tuos duomenis, suteikdamas galimybę didelių duomenų apdorojimui ir analizei atlikti daug efektyviau, nei buvo įmanoma anksčiau. Kita vertus, „Spark“ yra duomenų apdorojimo įrankis, veikiantis tuos paskirstytus duomenų rinkinius; tai nedaro paskirstytos saugyklos.
2: Galite naudoti vieną be kito. „Hadoop“ apima ne tik saugyklos komponentą, žinomą kaip „Hadoop“ paskirstytą failų sistemą, bet ir apdorojimo komponentą, vadinamą „MapReduce“, todėl jums nereikia „Spark“, kad atliktumėte apdorojimą. Priešingai, „Spark“ galite naudoti ir be „Hadoop“. „Spark“ neturi savo failų valdymo sistemos, todėl ją reikia integruoti su viena - jei ne HDFS, tai kita debesų pagrindu veikiančia duomenų platforma. „Spark“ buvo sukurtas „Hadoop“, tačiau daugelis sutinka, kad jie geriau kartu.
3: kibirkštis yra greitesnė. „Spark“ paprastai yra daug greitesnis nei „MapReduce“ dėl duomenų apdorojimo būdo. Kol „MapReduce“ veikia pakopomis, „Spark“ vienu ypu veikia visus duomenų rinkinius. „MapReduce darbo eiga atrodo taip: skaitykite duomenis iš sankaupos, atlikite operaciją, rašykite rezultatus į grupę, skaitykite atnaujintus duomenis iš grupės, atlikite kitą operaciją, rašykite kitus rezultatus į grupę ir pan.“, - aiškino Kirkas Borne'as, pagrindinis Boozo Alleno Hamiltono duomenų mokslininkas. Kita vertus, „Spark“ užbaigia visas duomenų analizės operacijas atmintyje ir beveik realiuoju laiku: „Skaitykite duomenis iš klasterio, atlikite visas reikalingas analitines operacijas, rašykite rezultatus į klasterį, atlikta“, - sakė Borne. Pasak jo, „Spark“ gali būti net 10 kartų greitesnis nei „MapReduce“ paketiniam apdorojimui ir iki 100 kartų greitesnis analizei atmintyje.
4: Jums gali neprireikti „Spark“ greičio. „MapReduce“ apdorojimo stilius gali būti puikus, jei jūsų duomenų operacijos ir ataskaitų teikimo reikalavimai dažniausiai yra statiniai ir galite palaukti, kol bus apdorotas paketiniu režimu. Bet jei jums reikia atlikti duomenų srauto analizę, pvz., Iš jutiklių gamyklos aukšte, arba turite programų, kurioms reikalingos kelios operacijos, tikriausiai norėtumėte naudoti „Spark“. Pavyzdžiui, daugumai mašininio mokymosi algoritmų reikia kelių operacijų. Dažniausios „Spark“ programos apima realaus laiko rinkodaros kampanijas, internetines produktų rekomendacijas, kibernetinio saugumo analizę ir mašinų žurnalų stebėjimą.
5: Nesėkmių atkūrimas: kitoks, bet vis tiek geras. „Hadoop“ yra natūraliai atsparus sistemos gedimams ar gedimams, nes duomenys įrašomi į diską po kiekvienos operacijos, tačiau „Spark“ turi panašų integruotą atsparumą dėl to, kad jos duomenų objektai yra saugomi vadinamuose elastinguose paskirstytuosiuose duomenų rinkiniuose, paskirstytuose per duomenų grupę. „Šie duomenų objektai gali būti laikomi atmintyje arba diskuose, o RDD suteikia galimybę visiškai atsigauti po gedimų ar gedimų“, - pabrėžė Borne.