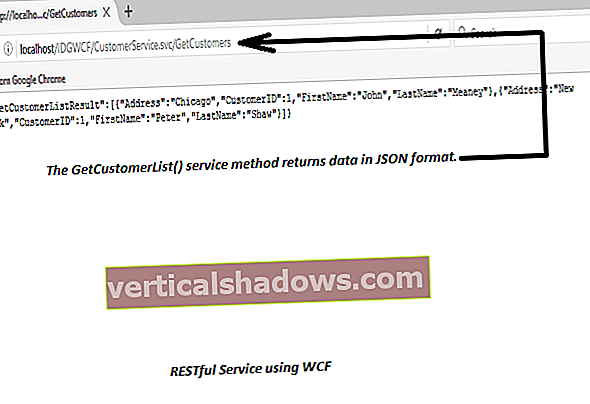
„Apache Solr“ yra atvirojo kodo paieškos variklis, tačiau tai yra kur kas daugiau. Tai „NoSQL“ duomenų bazė, palaikanti operacijas. Tai dokumentų duomenų bazė, siūlanti SQL palaikymą ir vykdanti ją paskirstytu būdu.
Anksčiau aš jums parodžiau, kaip sukurti ir įkelti kolekciją į „Solr“; galite įkelti tą kolekciją dabar, jei dar nebuvote jos darę anksčiau. (Visiškas atskleidimas: Aš dirbu „Lucidworks“, kuriame dirba daug pagrindinių „Solr“ projekto dalyvių.)
Šiame įraše aš jums parodysiu dar 10 dalykų, kuriuos galite padaryti su ta kolekcija:
1. Filtruokite užklausas
Apsvarstykite šią užklausą:
// localhost: 8983 / solr / ipps / select? fq = Provider_State: NC & indent = on & q = *: * & wt = json
Iš pažiūros ši užklausa atrodo panaši į tai, jei aš ką tik padariau q = Provider_State: NC. Tačiau filtravimo užklausos pateikia tik ID ir jos neturi įtakos balui. Filtro užklausos taip pat talpinamos. Tai geras būdas rasti tinkamiausią q = mėlyna zomša į skyrius: avalynė priešingai nei skyrius: drabužiai arba skyrius: muzika.

2. Susidūrimas
Išbandykite šią užklausą:
// localhost: 8983 / solr / ipps / select? facet = on &facet.field = Provider_State& facet.limit = -1 & įtrauka = įjungta & q = *: * & wt = json
Viršuje pateikiama:
 ID
ID„Faceting“ suteikia jums savo kategorijų skaičių (be kita ko). Jei diegiate mažmeninės prekybos svetainę, tai galite pateikti skyrių kategorijas ir kategorijų skaičių ar kitus būdus, kuriais galite padalyti savo atsargas.
3. Diapazono briaunojimas
Pridėkite tai prie užklausos eilutės: facet.interval = Average_Total_Payments & facet.interval.set = [0,1999.99] & facet.interval.set = [2000,2999.99] & facet.interval.set = [3000,3999.99] & facet.interval.set = [4000,4999.99] & aspektas. interval.set = [5000,5999.99] & facet.interval.set = [6000,6999.99] & facet.interval.set = [7000,7999.99] && facet.interval.set = [8000,8999.99] & facet.interval.set = [9000 , 10000]
Jūs gausite:

Šis diapazono briaunojimas gali padėti suskirstyti skaitinį lauką į diapazonų kategorijas. Jei kam nors padėsite rasti nešiojamą kompiuterį, kurio diapazonas yra 2000–3000 USD, tai jums. Panašią užklausą galite atlikti be kodavimo diapazonų, atlikdami tai: facet.range = Average_Total_Payments & facet.range.gap = 999.99 & facet.range.start = 2000 & facet.range.end = 10000
4. „DocValues“
Savo schemoje įsitikinkite, kad docValues laukams, su kuriais susiduriate, pasirinktas atributas. Tai optimizuoja lauką šioms paieškoms ir taupo atmintyje užklausos metu, kaip parodyta šioje schema.xml ištraukoje:
5. Pseudo laukai
Galite atlikti operacijas su savo duomenimis ir grąžinti vertę. Išbandyti šį:
// localhost: 8983 / solr / ipps / select? fl = Provider_Name,% 20Average_Total_Payments, price_category: if (min (0, sub (Average_Total_Payments, 5000)),% 22inexpensive% 22,% 22expensive% 22) & įtrauka = įjungta & q = * : * & eilutės = 10 & wt = json

Šiame pavyzdyje naudojamos kai kurios „Solr“ integruotos funkcijos, kad tiekėjai būtų klasifikuojami kaip brangūs ar nebrangūs, atsižvelgiant į vidutinį bendrą mokėjimą. aš dedu kainos_kategorija: jei (min (0, sub (Vidutinis_mokų_mokos, 5000)), „nebrangus“, „brangus“) viduje konors flarba laukų sąrašas kartu su dviem kitais laukais.
6. Užklausos analizatoriai
„defType“ leidžia pasirinkti vieną iš „Solr“ užklausos analizatorių. Numatytasis standartinis užklausų analizatorius yra tikrai tinkamas konkrečioms mašinų sugeneruotoms užklausoms. Bet „Solr“ taip pat turi „Dismax“ ir „eDismax“ analizatorius, kurie yra geresni įprastiems žmonėms: galite spustelėti vieną iš jų administratoriaus užklausos ekrano apačioje arba pridėti defType = dismax į savo užklausos eilutę. Paprastai „Dismax“ analizatorius pateikia geresnius vartotojo įvestų užklausų rezultatus, nes suranda „disjunkcijos maksimumą“ arba lauką, kuriame yra daugiausiai atitikčių, ir įtraukia jį į balą.
7. Stiprinimas
Jei ieškosite Provider_State: AL ^ 5 ARBA Provider_State: NC ^ 10, rezultatai Šiaurės Karolinoje bus įvertinti aukščiau nei rezultatai Alabamoje. Tai galite padaryti savo užklausoje (q = ""). Tai yra svarbus būdas manipuliuoti grąžintais rezultatais.

8. Datų intervalai
Nors pavyzdiniai duomenys nepalaiko jokių paieškų pagal dienų seką, jei taip būtų, jie būtų suformatuoti kaip timestamp_dt: [2016-12-31T17: 51: 44.000Z iki 2017-02-20T18: 06: 44.000Z]. „Solr“ palaiko datos tipo laukus ir datos tipo paieškas bei filtravimą.
9. TF-IDF ir BM25
Originalus vertinimo mechanizmas, kurį „Solr“ naudojo (norėdamas nustatyti, kurie dokumentai buvo susiję su jūsų paieškos terminu), vadinamas „TF-IDF“, reiškiančiu „terminų dažnis, palyginti su atvirkštiniu dokumento dažniu“. Pateikiama, kaip dažnai jūsų lauke ar dokumente yra terminas, palyginti su tuo, kaip dažnai šis terminas yra jūsų kolekcijoje. Šio algoritmo problema yra ta, kad „Sostų žaidimas“ įvyksta 100 kartų 10 puslapių dokumente, o dešimt kartų - 10 puslapių dokumente, todėl dokumentas nėra 10 kartų aktualesnis. Tai daro daugiau aktualu, bet ne 10 kartų daugiau Aktualus.
BM25 išlygina šį procesą, veiksmingai leisdamas dokumentams pasiekti prisotinimo tašką, po kurio bus sušvelnintas papildomų įvykių poveikis. Visos naujausios „Solr“ versijos pagal numatytuosius nustatymus naudoja „BM25“.
10. derinimasKlausimas
„Admin Query“ konsolėje galite patikrinti debugQuery, kad pridėtumėte debugQuery = įjungta prie „Solr“ užklausos eilutės. Jei patikrinsite rezultatus, rasite šį rezultatą:

Be kitų dalykų, jūs matote, kad naudojate „LuceneQParser“ (standartinio užklausų analizatoriaus pavadinimą) ir, aukščiau, kaip kiekvienas rezultatas buvo įvertintas. Matote patį BM25 algoritmą ir tai, kaip padidinimai paveikė rezultatą. Jei bandote derinti paiešką, tai yra labai vertingas įrankis!
Šie dešimt „Solr“ aspektų man tikrai padeda, kai naudoju „Solr“ paieškai ir koreguoju savo rezultatus.