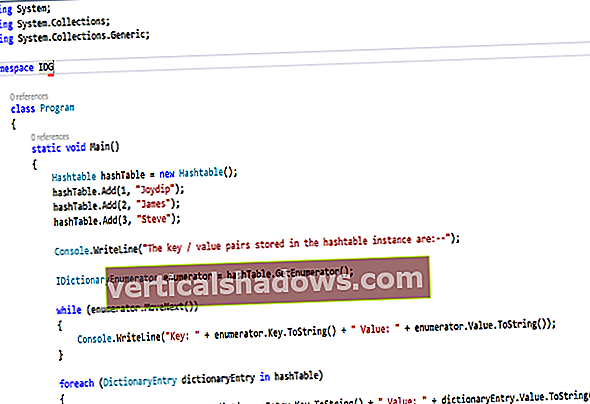
„Qubole“, mokama už debesų duomenų platformą, skirtą analizei, dirbtiniam intelektui ir mašininiam mokymuisi, siūlo klientų įtraukimo, skaitmeninės transformacijos, duomenimis pagrįstų produktų, skaitmeninės rinkodaros, modernizavimo ir saugumo žvalgybos sprendimus. Tai reikalauja greito vertės nustatymo laiko, kelių debesų palaikymo, 10 kartų didesnio administratoriaus našumo, 1: 200 operatoriaus ir vartotojo santykio ir mažesnių debesų išlaidų.
Tai, ką „Qubole“ iš tikrųjų daro, remdamasis mano trumpa patirtimi su platforma, yra integruoti daugybę atvirojo kodo įrankių ir keletą nuosavų įrankių, kad sukurtumėte debesų pagrindu veikiančią savitarnos didelių duomenų patirtį duomenų analitikams, duomenų inžinieriams. ir duomenų mokslininkai.
„Qubole“ nukreipia jus nuo ETL, atliekant tiriamąją duomenų analizę ir modelių kūrimą, iki modelių diegimo gamybos mastu. Be to, tai automatizuoja daugybę debesų operacijų, pvz., Atsarginių išteklių paskirstymą ir mastelį, kuriems kitu atveju gali prireikti daug administratoriaus laiko. Neaišku, ar ta automatika iš tikrųjų leis 10 kartų padidinti administratoriaus produktyvumą, ar 1: 200 operatoriaus ir vartotojo santykį bet kurioje konkrečioje įmonėje ar naudojimo atveju.
„Qubole“ linkusi galvoti apie „aktyvių duomenų“ sąvoką. Iš esmės daugumoje duomenų ežerų, kurie iš esmės yra failų saugyklos, užpildytos daugelio šaltinių duomenimis, visi vienoje vietoje, bet ne vienoje duomenų bazėje, yra mažas procentas duomenų, kurie aktyviai naudojami analizei. Qubole apskaičiavo, kad dauguma duomenų ežerų yra 10% aktyvūs ir 90% neaktyvūs, ir prognozuoja, kad jis gali pakeisti šį santykį.
„Qubole“ konkurentai yra „Databricks“, AWS ir „Cloudera“. Yra daugybė kitų produktų, kurie tik konkuruoja kai kurie Qubole funkcijų.
„Databricks“ sukuria bloknotus, informacijos suvestines ir užduotis ant klasterių tvarkytuvo ir „Spark“; Aš tai radau naudinga platforma duomenų mokslininkams, kai ją peržiūrėjau 2016 m. „Databricks“ neseniai atidarė savo „Delta Lake“ produktą, kuris teikia ACID operacijas, keičiamo dydžio metaduomenų tvarkymą ir vieningą srautinių ir paketinių duomenų apdorojimą duomenų ežerams, kad jie būtų patikimesni. ir padėti jiems atlikti kibirkščių analizę.
AWS turi platų duomenų produktų asortimentą, o iš tikrųjų „Qubole“ palaiko integraciją su daugeliu jų. „Cloudera“, kuriai dabar priklauso „Hortonworks“, teikia duomenų saugyklos ir mašininio mokymosi bei duomenų centro paslaugas. „Qubole“ tvirtina, kad tiek „Databricks“, tiek „Cloudera“ neturi finansų valdymo, tačiau valdymą galite įgyvendinti patys vieno debesies lygiu arba naudodami kelių debesų valdymo produktą.

Kaip veikia „Qubole“
„Qubole“ visus savo įrankius integruoja į debesies ir naršyklės aplinką. Aptarsiu aplinkos gabalus kitame šio straipsnio skyriuje; šiame skyriuje daugiausia dėmesio skirsiu įrankiams.
„Qubole“ vykdo sąnaudų kontrolę kaip savo grupių valdymo dalį. Galite nurodyti, kad klasteriai naudoja konkretų egzempliorių tipų derinį, įskaitant taškinius egzempliorius, jei jie yra, ir mažiausią ir didžiausią mazgų skaičių automatiniam keitimui. Taip pat galite nurodyti, kiek laiko klasteris toliau veiks be apkrovos, kad išvengtumėte „zombių“ atvejų.
Kibirkštis
Rugpjūčio straipsnyje „Kaip„ Qubole “sprendžia„ Apache Spark “iššūkius“, „Qubole“ generalinis direktorius Ashishas Suchoo aptaria „Spark“ pranašumus ir spąstus ir tai, kaip „Qubole“ pašalina tokius sunkumus kaip konfigūracija, našumas, sąnaudos ir išteklių valdymas. „Spark“ yra pagrindinis duomenų mokslininkų „Qubole“ komponentas, leidžiantis lengvai ir greitai transformuoti duomenis ir mokytis mašinomis.
Presto
„Presto“ yra atvirojo kodo paskirstytasis SQL užklausų variklis, skirtas interaktyvioms analitinėms užklausoms vykdyti nuo įvairaus dydžio duomenų šaltinių - nuo gigabaitų iki petabaitų. „Presto“ užklausos vykdomos daug greičiau nei „Hive“ užklausos. Tuo pačiu metu „Presto“ gali matyti ir naudoti „Hive“ metaduomenis ir duomenų schemas.
Avilys
„Apache Hive“ yra populiarus atvirojo kodo projektas „Hadoop“ ekosistemoje, palengvinantis didelių duomenų rinkinių, esančių paskirstytoje saugykloje, skaitymą, rašymą ir valdymą naudojant SQL. Struktūrą galima projektuoti į jau saugomus duomenis. Avilio užklausa vykdoma per „Apache Tez“, „Apache Spark“ arba „MapReduce“. Avilys „Qubole“ gali atlikti darbo krūvį suprantantį automatinį keitimą ir tiesioginį rašymą; atvirojo kodo aviliui trūksta šių į debesį orientuotų optimizacijų.
„Qubole“ įkūrėjai taip pat buvo „Apache Hive“ kūrėjai. Jie pradėjo „Hive“ „Facebook“ ir atidarė jį 2008 m.
Kvantas
„Quantum“ yra „Qubole“ serveris, automatinis mastelio keitimas, interaktyvus SQL užklausų variklis, palaikantis tiek „Hive DDL“, tiek „Presto SQL“. „Quantum“ yra „pay-as-you-go“ paslauga, kuri yra ekonomiška atsitiktinių užklausų modeliams, kurie skleidžiasi ilgą laiką, ir turi griežtą režimą, kad būtų išvengta netikėtų išlaidų. „Quantum“ naudoja „Presto“ ir papildo „Presto“ serverių sankaupas. Kvantinės užklausos ribojamos iki 45 minučių trukmės.
Oro srautas
„Airflow“ yra „Python“ pagrindu sukurta platforma, skirta programiškai kurti, planuoti ir stebėti darbo eigą. Darbo eigos yra nukreipti užduočių acikliniai grafikai (DAG). Konfigūruokite DAG, rašydami vamzdynus „Python“ kode. „Qubole“ siūlo „Airflow“ kaip vieną iš savo paslaugų; jis dažnai naudojamas ETL.
Naujasis „QuboleOperator“ gali būti naudojamas kaip ir bet kuris kitas esamas „Airflow“ operatorius. Vykdydamas operatorių darbo eigoje, jis pateiks komandą „Qubole Data Service“ ir palauks, kol komanda bus baigta. „Qubole“ palaiko failų ir „Hive“ lentelės jutiklius, kuriuos „Airflow“ gali naudoti programiškai stebėti darbo eigą.
Norėdami pamatyti „Airflow“ vartotojo sąsają, pirmiausia turite paleisti „Airflow“ grupę, tada atidarydami grupės puslapį, kad pamatytumėte „Airflow“ svetainę.
„RubiX“
„RubiX“ yra lengva „Qubole“ duomenų talpyklos sistema, kurią gali naudoti didelė duomenų sistema, naudojanti „Hadoop“ failų sistemos sąsają. „RubiX“ yra skirtas dirbti su debesies saugojimo sistemomis, tokiomis kaip „Amazon S3“ ir „Azure Blob Storage“, ir talpinti nuotolinius failus vietiniame diske. „Qubole“ išleido „RubiX“ atviram kodui. „RubiX“ įgalinimas „Qubole“ yra langelio žymėjimas.
Ką veikia „Qubole“?
„Qubole“ teikia „end-to-end“ platformą analizei ir duomenų mokslui. Funkcionalumas yra paskirstytas maždaug keliolikai modulių.
Naršymo modulis leidžia peržiūrėti duomenų lenteles, pridėti duomenų saugyklas ir nustatyti duomenų mainus. AWS galite peržiūrėti duomenų ryšius, S3 segmentus ir „Qubole Hive“ duomenų saugyklas.
„Analyze“ ir „Workbench“ moduliai leidžia vykdyti ad hoc užklausas savo duomenų rinkiniuose. „Analyze“ yra sena sąsaja, o „Workbench“ yra nauja sąsaja, kuri vis dar buvo beta versijoje, kai bandžiau. Abi sąsajos leidžia nuvilkti duomenų laukus į SQL užklausas ir pasirinkti variklį, kurį naudojate operacijoms vykdyti: „Quantum“, „Hive“, „Presto“, „Spark“, duomenų bazę, „shell“ arba „Hadoop“.
„Smart Query“ yra „SQL“ užklausų kūrimo priemonė, skirta „Hive“ ir „Presto“. Šablonai leidžia pakartotinai naudoti parametruojamas SQL užklausas.
Nešiojamieji kompiuteriai yra „Spark“ pagrindu sukurti „Zeppelin“ arba (beta versijoje) „Jupyter“ sąsiuviniai, skirti duomenų mokslui. Informacijos suvestinės suteikia sąsają, skirtą dalytis jūsų tyrimais, neleidžiant prieigos prie jūsų užrašų knygelių.
Tvarkaraštis leidžia automatiškai vykdyti užklausas, darbo eigą, duomenų importavimą ir eksportavimą bei komandas. Tai papildo ad-hoc užklausas, kurias galite vykdyti „Analyze“ ir „Workbench“ moduliuose.
„Clusters“ modulis leidžia jums valdyti „Hadoop / Hive“, „Spark“, „Presto“, „Airflow“ ir „deep learning“ (beta) serverių grupes. Naudojimas leidžia stebėti klasterio ir užklausos naudojimą. Valdymo skydelyje galite konfigūruoti platformą sau arba kitiems, jei turite sistemos administravimo leidimus.
„Qubole“ perėjimas iki galo
Peržiūrėjau duomenų bazės importavimo, „Hive“ schemos kūrimo analizę ir analizuodamas rezultatą naudodamas „Hive“ ir „Presto“ bei atskirai „Spark“ sąsiuvinyje. Aš taip pat žiūrėjau į „Airflow DAG“ dėl to paties proceso ir į užrašų knygelę, skirtą mašininiam mokymuisi atlikti su „Spark“ pagal nesusijusį duomenų rinkinį.














Gilus mokymasis Qubole
Mes matėme duomenų mokslą Qubole iki klasikinio mašininio mokymosi lygio, bet kaip yra su giluminiu mokymusi? Vienas iš būdų atlikti gilų mokymąsi „Qubole“ yra į jūsų bloknotus įterpti „Python“ veiksmus, importuojančius gilias mokymosi sistemas, tokias kaip „TensorFlow“, ir naudoti juos duomenų rinkiniuose, kurie jau sukurti naudojant „Spark“. Kitas dalykas yra skambinti „Amazon SageMaker“ iš užrašų knygelių ar „Airflow“, darant prielaidą, kad jūsų „Qubole“ diegimas veikia AWS.
Daugumai to, ką darote „Qubole“, nereikia naudoti GPU, tačiau norint giliai mokytis, dažnai reikia GPU, kad mokymai būtų baigti per pagrįstą laiką. „Amazon SageMaker“ tuo rūpinasi vykdydamas giluminius mokymosi žingsnius atskirose grupėse, kurias galite sukonfigūruoti naudodami tiek mazgų ir GPU, kiek reikia. „Qubole“ taip pat siūlo mašininio mokymosi grupes (beta versijoje); AWS tai leidžia naudoti pagreitintus „G“ ir „P“ tipo darbuotojus su „Nvidia“ GPU, o „Google Cloud Platform“ ir „Microsoft Azure“ - lygiaverčius pagreitintus darbuotojų mazgus.
Didžiųjų duomenų įrankių rinkinys debesyje
„Qubole“ - debesyje naudojama duomenų platforma, skirta analizei ir mašininiam mokymuisi, padeda importuoti duomenų rinkinius į duomenų ežerą, kurti schemas naudojant „Hive“ ir pateikti užklausą duomenims naudojant „Hive“, „Presto“, „Quantum“ ir „Spark“. Jis naudoja tiek užrašų knygutes, tiek „Airflow“ kurdamas darbo eigą. Jis taip pat gali kreiptis į kitas tarnybas ir naudoti kitas bibliotekas, pavyzdžiui, „Amazon SageMaker“ paslaugą ir „TensorFlow Python“ biblioteką giliam mokymuisi.
„Qubole“ padeda valdyti debesijos išlaidas, valdydama grupių egzempliorių derinį, paleidžiant ir automatiškai plečiant grupes pagal poreikį ir automatiškai išjungiant grupes, kai jos nenaudojamos. Jis veikia AWS, „Microsoft Azure“, „Google Cloud Platform“ ir „Oracle Cloud“.
Apskritai, „Qubole“ yra labai geras būdas pasinaudoti (arba „suaktyvinti“) savo duomenų ežerą, izoliuotas duomenų bazes ir didelius duomenis. Galite 14 dienų nemokamai išbandyti „Qubole“ pasirinkdami AWS, „Azure“ ar GCP su duomenų pavyzdžiais. Be to, naudodamiesi savo debesies infrastruktūros paskyra ir savo duomenimis, galite surengti nemokamą visų funkcijų bandymą iki penkių vartotojų ir vieną mėnesį.
—
Kaina: Bandomosios ir bandomosios sąskaitos, nemokamos. „Enterprise“ platforma - 0,14 USD už QCU („Qubole Compute Unit“) per valandą.
Platforma: „Amazon Web Services“, „Google Cloud Platform“, „Microsoft Azure“, „Oracle Cloud“.